python3提取免费高匿代理
写爬虫总是免不了被ban ip,限制流量等问题,有个高效的ip代理池还是很重要的,这里我们就介绍如何从已有公开代理总提取有效ip组建自己高效的爬虫代理池
主要以下几个模块
1.requests爬取代理 2.更新检测可用代理
requests爬取代理,选取xici代理为例
高匿网页地址xici, 检查元素
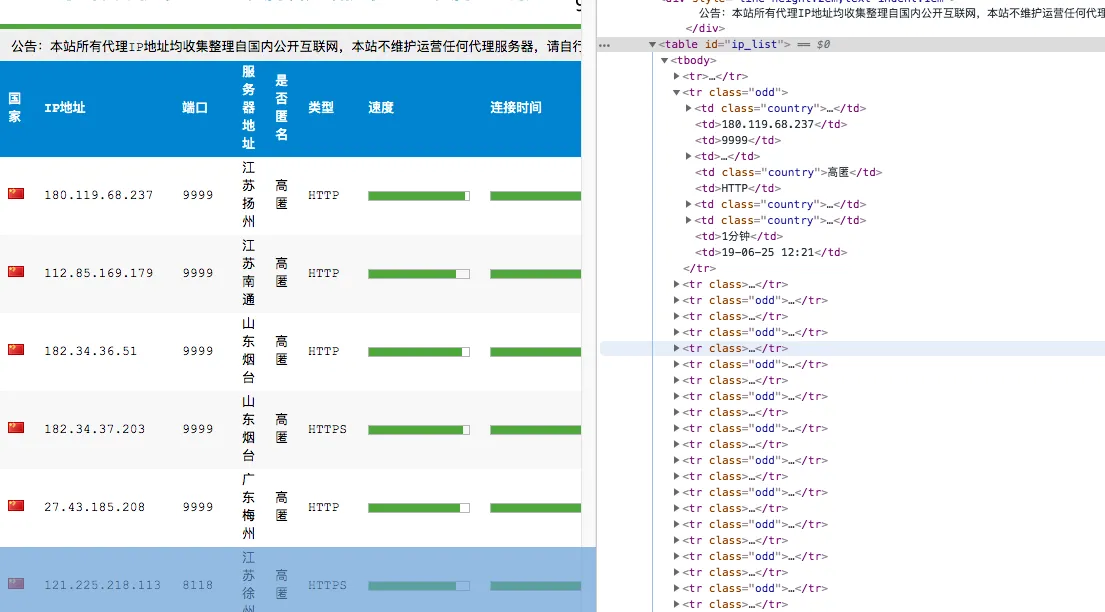
元素选择就是id为ip_list的tr为一个一个的代理,td下为详细信息,因此css选择器就可以为 content.css("#ip_list").css(“tr”) ,然后在提取1,6项即可,后续加入判断ip可用性选项,判断成功后存入json文件,以后就可以通过http形式获取到可用的代理信息。
#!/root/anaconda3/bin/python
from scrapy.selector import Selector
import redis
import requests
import json
import requests
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
import random
def get_headers():
USER_AGENT_LIST = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; 360SE)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET4.0C; .NET4.0E; 360SE)'
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763',
'"Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
]
USER_AGENT = random.choice(USER_AGENT_LIST)
return {'User-Agent':USER_AGENT}
def get_random_proxy():
https_pro=[i for i in pro if "https" in i]
if len(https_pro)==0:
return None
else:
return https_pro[random.randint(0,len(https_pro))]
def crawl_ip():
for i in range(5):
rand_ip = get_random_proxy()
if rand_ip:
r =requests.get('https://www.xicidaili.com/nn/{}'.format(str(i+1)),headers=get_headers())
else:
r =requests.get('https://www.xicidaili.com/nn/{}'.format(str(i+1)),headers=get_headers(),proxies=proxies_ip(rand_ip))
content = Selector(r)
ip_list = content.css("#ip_list").css("tr")
for i in ip_list[1:]:
info = i.css("td::text").extract()
ip = info[0]
protoco = info[5].strip().lower()
if protoco=="http" or protoco=="https":
url = protoco + '://' + ip + ':' + info[1]
else:
url = 'http://' + ip + ':' + info[1]
validate_ip(url)
def proxies_ip(url):
if 'https' not in url:
proxies={'http':url}
else:
proxies={'https':url}
return proxies
def validate_ip(url):
proxies = proxies_ip(url)
if url not in pro:
bobo_url=http_url
if "https" in url:
bobo_url=https_url
try:
r = requests.get(bobo_url, headers=get_headers(), proxies=proxies, timeout=1)
pro.append(url)
print('ip %s validated' % url)
except Exception as e:
print('cant check ip %s' % url)
def check_current_ip():# 更新检测可用代理
curr = open(JSON_PATH).read()
if curr!='':
for url in json.loads(open(JSON_PATH).read()):
validate_ip(url)
if __name__ =='__main__':
http_url = "http://www.bobobk.com"
https_url = "https://www.bobobk.com"
pro = []
TXT_PATH = '/www/wwwroot/default/daili.txt'
JSON_PATH='/www/wwwroot/default/daili.json'
PROXYCHAIN_CONF='/www/wwwroot/default/proxy.conf'
check_current_ip()
crawl_ip()
with open(JSON_PATH,'w') as fw:
fw.write(json.dumps(list(set(pro))))
fw.close()
with open(TXT_PATH,'w') as fw:
for i in set(pro):
fw.write(i+"\n")
fw.close()
更新检测可用代理
程序每次抓取页面前先检测可用代理,然后自动使用可用代理来抓取新的代理,可以稳定运行。 这里设置一下定时运行,那么就可以每小时自动更新代理信息
crontab -e
调用定时任务,加入当前脚本,就可以。 本人服务器实例
0 */1 * * * /www/service/daili.py >> /www/service/daili.log 2>&1
最后访问127.0.0.1/daili.txt就可以看到搜集到的代理了
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/352.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。