利用谷歌浏览器测试接口技巧
在编写爬虫的时候,经常会因为手动修改header和cookie之类的问题弄得焦头烂额,总是出错,这里介绍一个非常方便的利用chrome自带的工具进行python版本的requests请求。
准备工具:
1.chrome
步骤
1.首先浏览器中打开网络调试工具,这里以12306的查询余票为例。
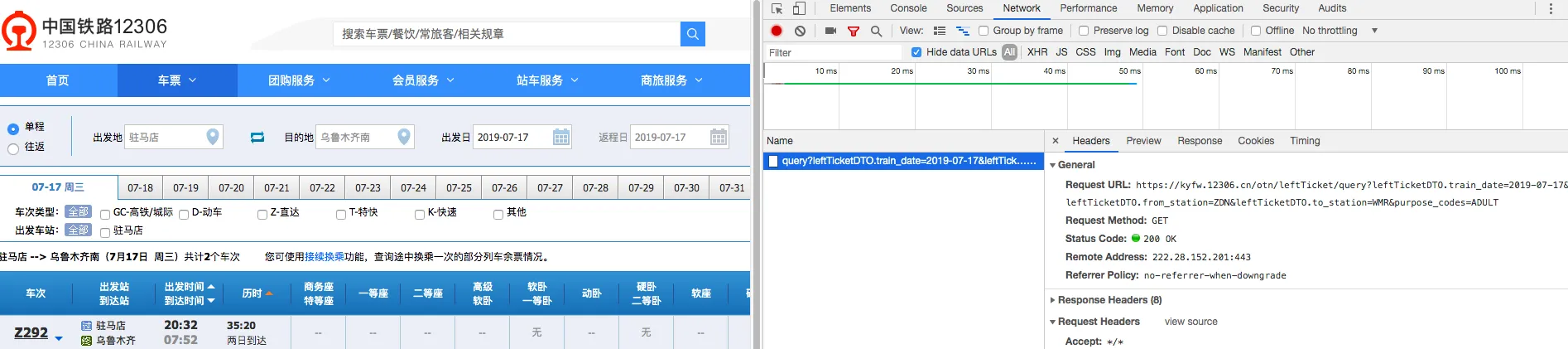
2.查询就可以看到我们的请求了,使用copy as curl就可以获得curl版本的请求了。
curl是linux下的一个用于下载的程序。
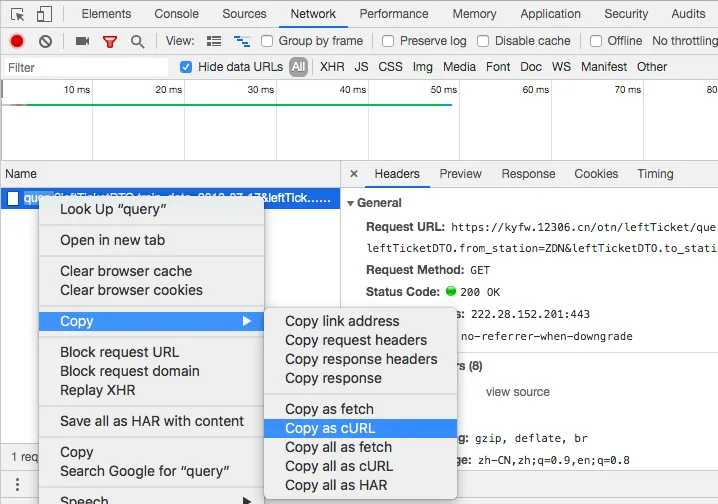
3.转换成python版本的requests
这里可以使用已有的工具进行,一个现成的可转换成多种变成语言的网页版本。
网址 https://curl.trillworks.com 把我们上一步获得的curl请求粘贴到框里,右边就获得了python版本的数据,如我们查询驻马店到乌鲁木齐的票。
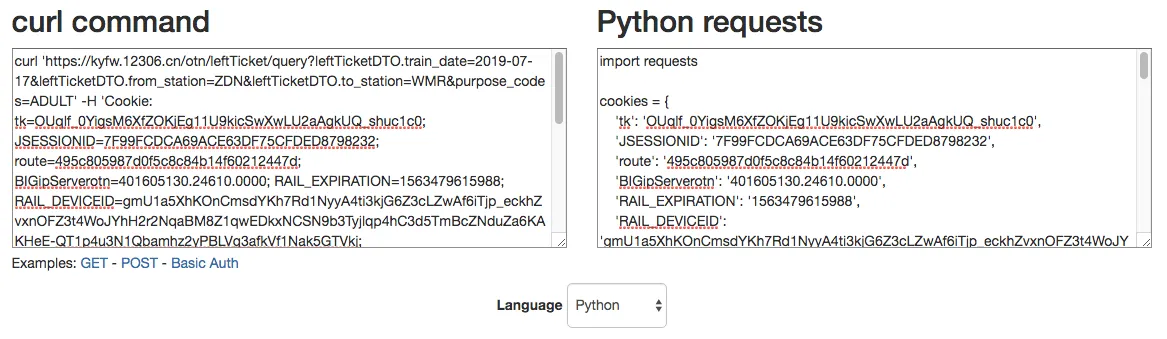 最后的python版本就是
最后的python版本就是
import requests
cookies = {
'tk': 'OUqlf_0YigsM6XfZOKjEg11U9kicSwXwLU2aAgkUQ_shuc1c0',
'JSESSIONID': '7F99FCDCA69ACE63DF75CFDED8798232',
'route': '495c805987d0f5c8c84b14f60212447d',
'BIGipServerotn': '401605130.24610.0000',
'RAIL_EXPIRATION': '1563479615988',
'RAIL_DEVICEID': 'gmU1a5XhKOnCmsdYKh7Rd1NyyA4ti3kjG6Z3cLZwAf6iTjp_eckhZvxnOFZ3t4WoJYhH2r2NqaBM8Z1qwEDkxNCSN9b3Tyjlqp4hC3d5TmBcZNduZa6KAKHeE-QT1p4u3N1Qbamhz2yPBLVg3afkVf1Nak5GTVkj',
'BIGipServerpool_passport': '250413578.50215.0000',
'_jc_save_fromStation': '%u9A7B%u9A6C%u5E97%2CZDN',
'_jc_save_toStation': '%u4E4C%u9C81%u6728%u9F50%u5357%2CWMR',
'_jc_save_wfdc_flag': 'dc',
'_jc_save_fromDate': '2019-07-17',
'_jc_save_toDate': '2019-07-17',
}
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Accept': '*/*',
'Cache-Control': 'no-cache',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'If-Modified-Since': '0',
'Referer': 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=%E9%A9%BB%E9%A9%AC%E5%BA%97,ZDN&ts=%E4%B9%8C%E9%B2%81%E6%9C%A8%E9%BD%90%E5%8D%97,WMR&date=2019-07-17&flag=N,N,Y',
}
params = (
('leftTicketDTO.train_date', '2019-07-17'),
('leftTicketDTO.from_station', 'ZDN'),
('leftTicketDTO.to_station', 'WMR'),
('purpose_codes', 'ADULT'),
)
response = requests.get('https://kyfw.12306.cn/otn/leftTicket/query', headers=headers, params=params, cookies=cookies)
#NB. Original query string below. It seems impossible to parse and
#reproduce query strings 100% accurately so the one below is given
#in case the reproduced version is not "correct".
# response = requests.get('https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2019-07-17&leftTicketDTO.from_station=ZDN&leftTicketDTO.to_station=WMR&purpose_codes=ADULT', headers=headers, cookies=cookies)
总结
文章介绍了如何从浏览器中提取可以在python中使用的requests请求,可以很方便的给爬虫使用,避免手动设置各种参数的繁琐和错误。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/410.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。