scrapy爬取表情包使用flask搭建搜索网站
今天跟师弟聊天说到他花钱从淘宝购买表情包,而我自身的表情包也不多,但是网上有很多表情包网站,何不自己爬取搭一个表情包搜索网站呢?因此本文以doutula为演示站点,详细说明从网上使用scrapy爬取表情包并最终搭建一个自己的表情包搜索网站的过程。主要步骤如下:
- scrapy爬取表情包并存入mysql
- flask搭建搜索网站
- 每日更新保存图片到本地 准备工作,anaconda python3
pip install scrapy
pip install flask
pip install pymysql
scrapy爬取表情包并存入mysql
打开网站审查元素
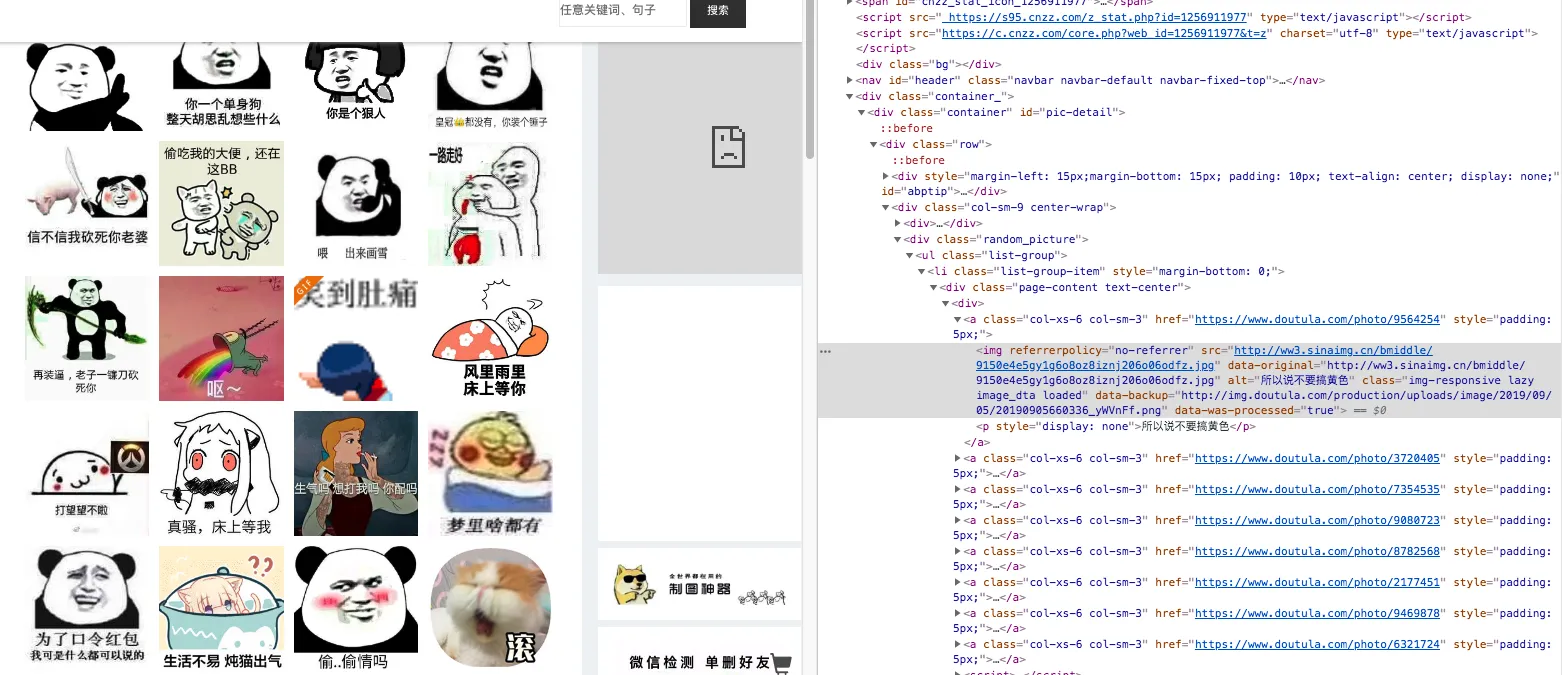 确定css提取规则与mysql表结构。
可以看到主要字段有两个,
确定css提取规则与mysql表结构。
可以看到主要字段有两个,
- 一个为图片地址,可以看到为新浪来源,确定字段 image_url 。
- 一个为表情包描述,在p元素里面,字段为_image_des_ 。
- 另外需要一个主键,设为 id 。后续搜索表情包的时候根据描述字段查出表情包地址,直接外链就行。
创建一个表情包的数据库和表
create dataabse bqb;
use bqb;
DROP TABLE IF EXISTS `bqb_scrapy`;
CREATE TABLE `bqb_scrapy` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`image_url` varchar(100) NOT NULL,
`image_des` varchar(100) NOT NULL,
PRIMARY KEY (`id`),
KEY `image_url` (`image_url`)
) ENGINE=InnoDB AUTO_INCREMENT=187800 DEFAULT CHARSET=utf8mb4;
3个字段,自增id,图片地址,图片描述。
编写scrapy爬虫
class DoutulaSpider(scrapy.Spider):
name = 'doutula'
allowed_domains = ['doutula.com']
start_urls = ['https://www.doutula.com/photo/list/']
for i in range(2,2773):
start_urls.append("https://www.doutula.com/photo/list/?page={}".format(i))
def parse(self, response):
item = {}
item['image_url'] = response.css("div.random_picture").css("a>img::attr(data-original)").extract()
item['image_des'] = response.css("div.random_picture").css("a>p::text").extract()
yield item
表情包一共有2773页,爬取规则 response.css(“div.random_picture”).css(“a>img::attr(data-original)”).extract() 可以获得一个表情包地址的list,而 item[‘image_des’] = response.css(“div.random_picture”).css(“a>p::text”).extract() 可以得到表情包的描述
编写scrapy pipline存入mysql
import pymysql
class BqbPipeline(object):
def open_spider(self,spider):
self.mysql_con = pymysql.connect('localhost', 'youruser', 'yourpass', 'bqb',autocommit=True)
self.cur = self.mysql_con.cursor()
def process_item(self, item, spider):
for i in range(len(item['image_url'])):
query = 'insert into bqb_scrapy(`image_url`,`image_des`) values("{}","{}");'.format(item['image_url'][i],item['image_des'][i])
self.cur.execute(query)
return item
def close_spider(self, spider):
self.mysql_con.close()
pymysql的使用,在mysql数据库连接中使用autocommit使得自动确认插入操作。
item等以及scrapy开始爬取
接下来需要把setting.py的pipeline注释部分取消使得存入数据库操作可以起作用,另外就是item.py确定item中的两个元素
import scrapy
class BqbItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
image_des = scrapy.Field()
运行爬虫就可以了,在项目根目录运行
scrapy crawl doutula
可以看到数据在疯狂地存入数据库了
 到这里,第一步scrapy爬取表情包并存入mysql数据库就已经完成了。
到这里,第一步scrapy爬取表情包并存入mysql数据库就已经完成了。
flask搭建搜索网站
flask app中需要三个页面,首页,搜索并展示功能,404页面。 网站主程序 bqb.py
import pymysql
from flask import Flask
from flask import request, render_template
app = Flask(__name__)
def db_execute(keyword):
conn = pymysql.connect('localhost', 'youruser', 'yourpass', 'bqb')
query = 'select image_url,image_des from bqb_scrapy where image_des like "%{}%" limit 1000;'.format(keyword)
cur = conn.cursor()
cur.execute(query)
res = cur.fetchall()
cur.close()
conn.close()
return res
@app.route('/', methods=['GET', 'POST'])
def search():
if request.method == 'GET':
return render_template('index.html')
elif request.method == 'POST':
keyword = request.form.get('keyword').strip()
items = db_execute(keyword)
if items != None:
return render_template('bqb.html', list=items)
else:
return 'not found'
else:
return render_template('404.html')
if __name__ == '__main__':
#print(db_execute(u"呵呵"))
app.run(host='0.0.0.0',port=555)
这样就完成了,本地444端口,使用nginx反向代理就行,域名为 bqb.bobobk.com,查看效果
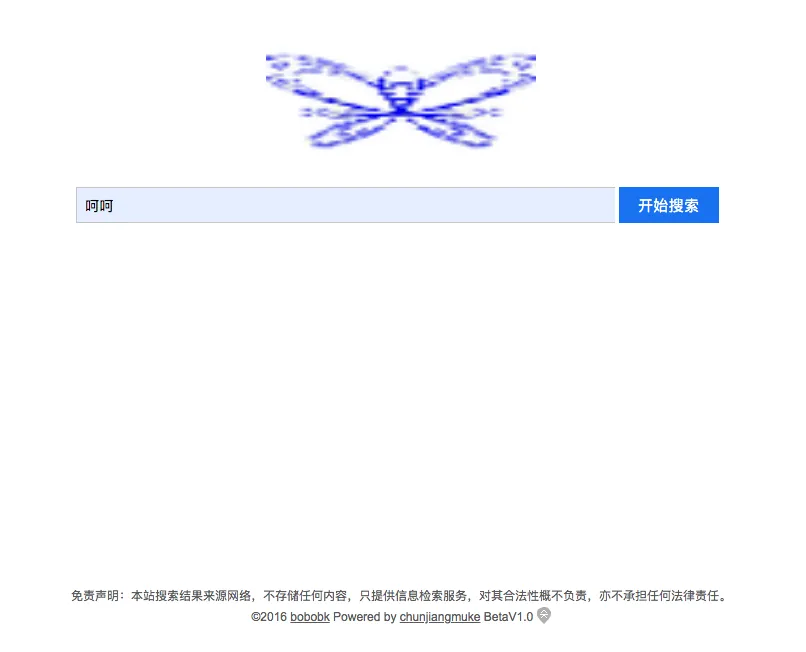

这样一个表情包搜索网站就搭好了,斗图的时候再也不用担心没有表情包可用了。
每日更新保存图片到本地
在表情包搜索网站运行一段时间后,发现图片无法直接加载了,因此决定将图片存到本地,以后就不会出现加载不出来的情况了。由于现在数据库已经存了几十万的表情包了,那么全部放在一个文件夹明显不太合适,在网上找到了存放大量小文件的思路,就是把文件id进行32进制的转换并将其补零至6位,随后进行2个2个的拆分位3个文件夹,分别进行存储就可以了。因此首先将数据库导出到csv,然后通过python调用wget实现了,方法如下:
首先导出表情包数据库到csv
导出mysql数据库到csv,这里你可以采用phpmyadmin或者直接登陆数据库使用select into file导出
use bqb;
select * from bqb_scrapy into outfile "bqb.csv";
在数据库中到处csv文件到当前文件夹下
图片下载并存入本地
为了防止新浪ban了我的ip,这里就慢慢的下载,没有使用多线程了。 python 下载图片代码
### 导入包
import pandas as pd
import numpy as np
import os
### 确认文件保存文件夹的存在,linux下的mkdir -p可以很好地解决迭代创建文件夹的任务
def check_path(string1):
if os.path.exists(string1):
pass
else:
os.system("mkdir -p {}".format(string1))
### 通过数据库的自增id确定文件应该保存到的文件夹位置
def get_dir(num):
num_hex = hex(num)[2:].zfill(6)
return "/".join(["..",str(num_hex[:2]),str(num_hex[2:4])])
### 文件不存在或者为空时调用wget下载文件到指定文件夹
def request_file(url,filename):
if not os.path.exists(filename) or os.path.getsize(filename) == 0:
cmd = "wget {} -qO {}".format(url,filename)
os.system(cmd)
### 读取前面导出的mysql数据表,read_csv中的usecols很好用,可以过滤字符中的逗号
df = pd.read_csv("bqb.csv",header=None,usecols=range(4),names=["id","url","des","bool"])
### 下载所有的表情包图片文件
for i in df.index:
url = df["url"][i].replace("'",'') ##导出的文件字符串有引号,这里去掉
fdir = df["id"][i]
path_dir = get_dir(fdir)
check_path(path_dir)
filename = path_dir+"/"+url.split("/")[-1]
request_file(url,filename)
这里本文采用了两级文件夹,每个文件夹保存16**2次方的文件个数。在调用wget下载文件前,首先通过check_path函数保证文件夹的存在。下载文件时确认文件不存在或者为空才下载。详细解释看代码就好了。
为了更好的展示图片,表情包站采用了瀑布流的展示方式。
查看下第二个版本的表情包网站效果吧

总结
本文从头开始使用scrapy从表情包网站抓取表情包,并随后使用flask部署网站,在新浪图片无法加载时,将图片下载到本地生成了第二版的表情包搜索网站,由于免费cdn的流量限制问题,这里每次搜索出来的表情包限制为20个。有了表情包搜索网站,你们就是最靓的仔。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/471.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。