机器学习中混淆矩阵详解
机器学习中,首先搜集数据,清理数据,预处理算法设计,那么如何知道算法的有效性呢?如何评估预测模型能不能有效地进行分类以及分类准确性如何,这就涉及到这里要说的混淆矩阵,混淆矩阵被广泛应用于评估机器学习的分类问题的(主要是监督学习)。本文将会包括下面几个部分。
- 什么是混淆矩阵
- 二分类问题的混淆矩阵计算
什么是混淆矩阵
分类问题中,机器学习的算法评估中分为4个概念,分别是
(1)若一个实例是正类并且被预测为阳性,即为真阳性(True Postive TP) (2)若一个实例是阳性,但是被预测成为阴性,即为假阴性(False Negative FN) (3)若一个实例是阴性,但是被预测成为阳性,即为假阴性(False Postive FP) (4)若一个实例是阴性,预测成为阴性,即为真阴性(True Negative TN),如下表所示
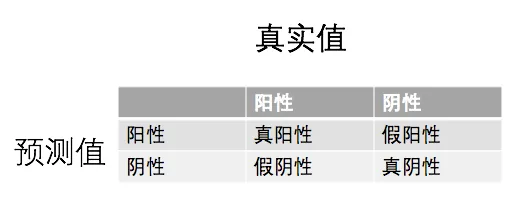 下面具体说明,假设对于一个怀孕的检查来说。
下面具体说明,假设对于一个怀孕的检查来说。

真阳性:
你预测或者说检测为真,检测结果准确。 就是说你的检查结果显示一个妇女怀孕了,真实结果是她确实是怀孕了。
真阴性:
预测结果显示为假但是实际结果却是真。 检查显示该妇女没有怀孕,而真实结果是她怀孕了。
假阳性(一型错误):
预测结果显示为真,但真实结果是假。 该例中,一个男人在检测结果显示为怀孕了,真实情况是他没有怀孕。
假阴性(二型错误):
预测结果显示为假,但真实情况为真。 该例中,一个妇女检测结果显示为没怀孕,但真实情况是她怀孕了。
总的来说判断方法为首先预测是阳性还是阴性,然后看判断的真假情况。 预测为真,预测正确,那么是真阳性。 预测为真,预测错误,那么是假阳性。 预测为假,预测正确,那么是真阴性。 预测为假,预测错误,那么是假阴性。
二分类问题的混淆矩阵计算
知道了混淆矩阵的内容,接下来就是各项参数的计算了,主要就是recall,precision,accuracy
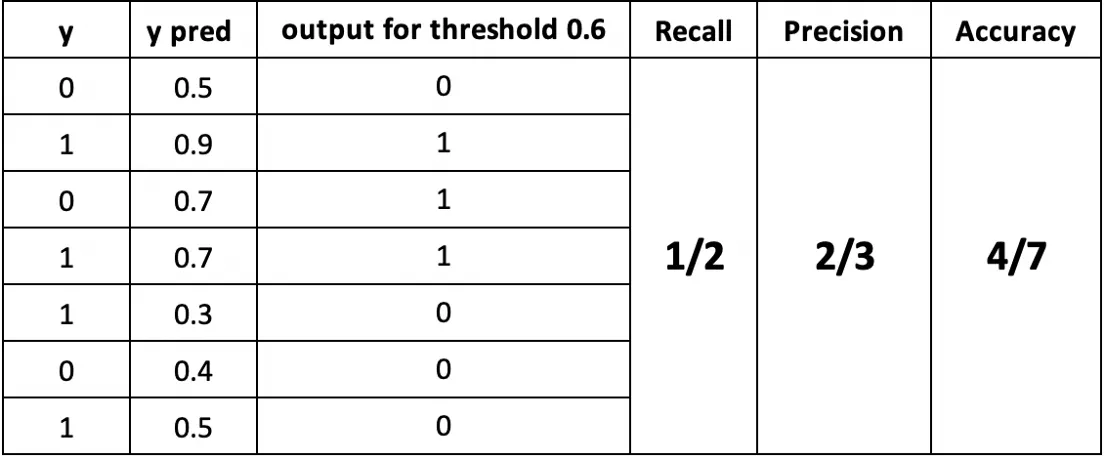
recall计算
recall = TP/(TP+FN)
描述就是在所有真实情况为真的样本中,被预测为真所占的比例,由定义可知recall越高越好。 例子中,第2,4,5,7个样本为真,预测显示2,4为真那么recall就是2/4=1/2
precision计算
precision = TP/(TP+FP)
描述就是在所有预测为真的样本中,确实为真的样本所占的比例,越高越好。 例子里,一共预测了3个样本(第2,3,4个样本)为真,真实为真的是第2,4,因此为2/3.
accuracy 计算
accuracy = (TP+TN)/(TP+FP+TN+FN)
描述为所有样本中分类正确样本所占的比例,当然也是越高越好。 例子中一共7个样本,其中1,2,4,6样本分类正确,因此accuracy就是4/7
实际情况中,如果两个算法在recall和precision表现不一致时,怎么比较优劣呢?这里介绍一个应用广泛的参数f-measure.
f-measure 计算
f-measure翻译为F值
f_measure = 2*recall*precision/(recall + precision)
f值同时参考了recall和precision的参数,可以用于不同算法的优劣性比较。
总结
本文介绍了机器学习中用于评价模型好坏的混淆矩阵,具体的概念以及在实际情况中如何计算模型的各个参数。
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/932.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。