预处理方法Scale,Standardize,Normalize的选择
很多机器学习的方法都要求数据近似正态分布并尽可能接近,而python中用于机器学习的包便是sklearn,其提供包括MinMaxScaler,RobustScaler,StandardScaler和Normalizer在内的多种函数用于机器学习的预处理,那么这些方法应该如何选择呢?首先我们介绍下区别然后采用实际数据进行处理查看数据处理前后的变化,最后再来做一个总结.
定义
scale: 通常意味着更改值的范围,而保持分布的形状不会发生改变.就跟实物和模型一样,这就是为什么我们说它是按比例变化的。 该范围通常设置为 0 到 1。 standardize: 标准化通常更改数值使得分布的标准差等于1。 normalize: 该表达可用于上述两种处理,因此为防止混淆,应避免使用.
原因
那么为什么要进行标准化与归一化呢?
这是因为多种算法在处理标准化或者归一话后的数值时速度更快.比如:
- 线性回归
- KNN
- NN
- SVM
- PCA
- LDA
生成测试数据
数据生成使用np.random下的函数生成,这里分别生成beta分布,exponential分布,正态分布以及中心和范围变化的正态分布.代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置种子,保证数据可重现
np.random.seed(1024)
data_beta = np.random.beta(1,2,1000)
data_exp = np.random.exponential(scale=2,size=1000)
data_nor = np.random.normal(loc=1,scale=2,size=1000)
data_bignor = np.random.normal(loc=2,scale=5,size=1000)
# 生成dataframe
df = pd.DataFrame({"beta":data_beta,"exp":data_exp,"bignor":data_bignor,"nor":data_nor})
df.head()
# beta exp bignor nor
# 0 0.383949 1.115062 5.681630 3.384865
# 1 0.328885 0.831677 7.175799 3.036709
# 2 0.048446 8.407472 4.119069 -2.049115
# 3 0.108803 8.125079 10.164492 1.026024
# 4 0.376316 2.721583 6.848210 3.390942
查看该数据集的分布曲线
sns.displot(df.melt(),x="value",hue="variable",kind="kde")
plt.savefig("origin.png",dpi=200)
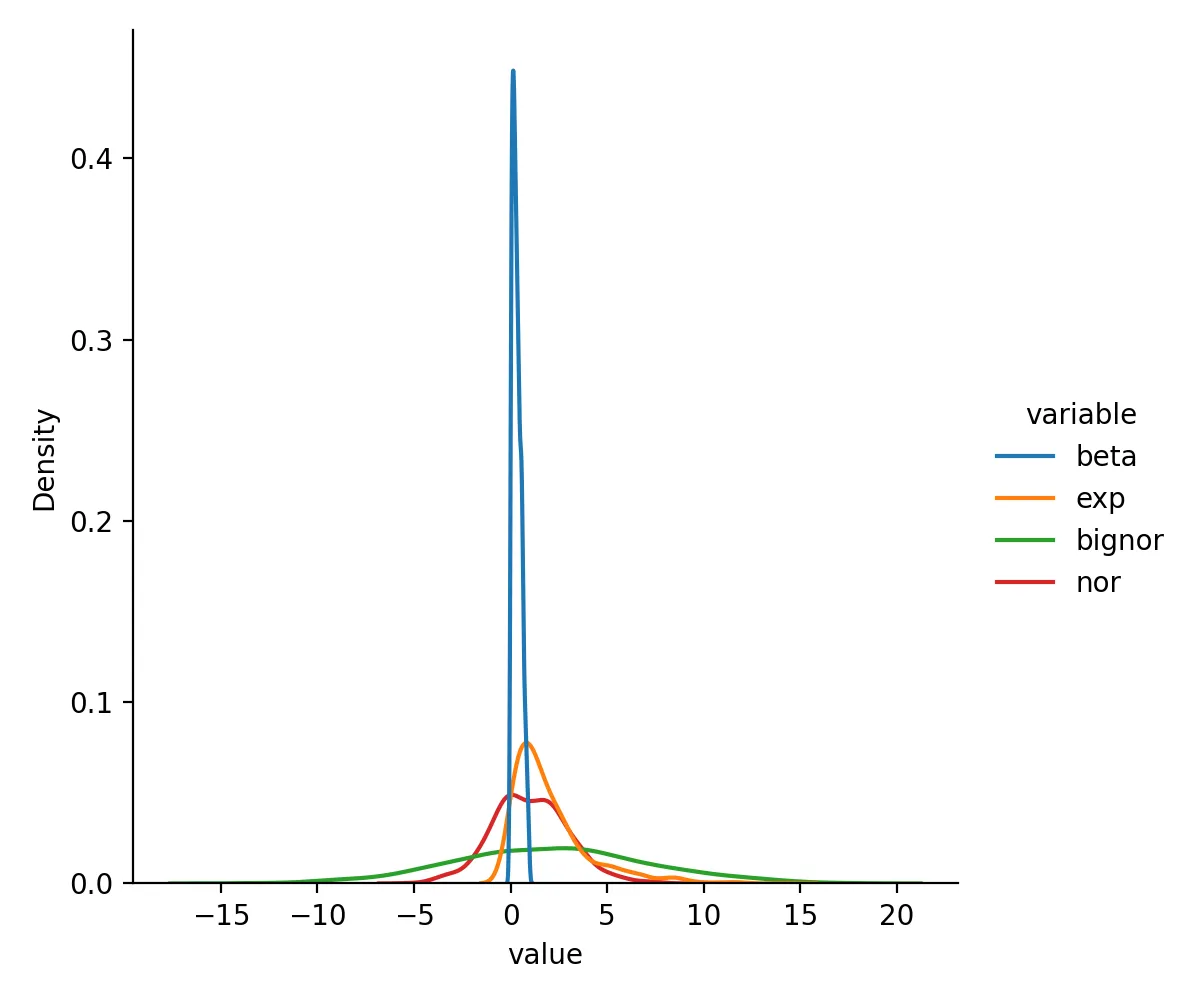
比较不同处理后数据变化情况
分别使用MinMaxScaler,RobustScaler和StandardScaler进行处理并比较
MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
df_minmax = pd.DataFrame(MinMaxScaler().fit(df).transform(df), columns = df.columns)
sns.displot(df_minmax.melt(),x="value",hue="variable",kind="kde")
plt.savefig("minmaxscaler.png",dpi=200)
plt.close()
MinMaxScaler转换后数据变成这样
beta exp bignor nor
0 0.402556 0.077887 0.623988 0.662302
1 0.344735 0.058066 0.671804 0.635879
2 0.050261 0.587947 0.573984 0.249901
3 0.113638 0.568196 0.767447 0.483282
4 0.394540 0.190253 0.661321 0.662763
分布为
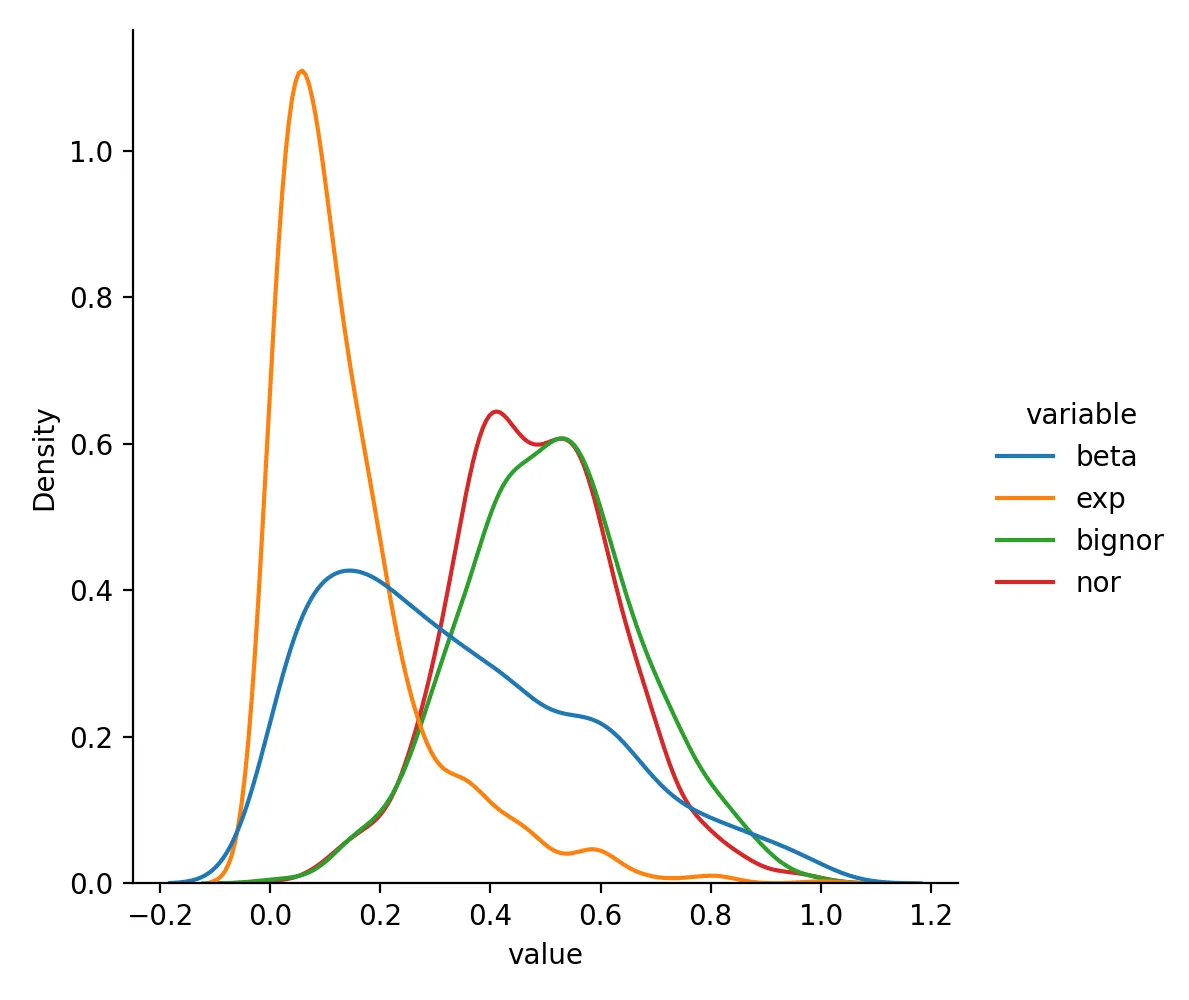
RobustScaler
from sklearn.preprocessing import RobustScaler
df_rsca = pd.DataFrame(RobustScaler().fit(df).transform(df), columns = df.columns)
sns.displot(df_rsca.melt(),x="value",hue="variable",kind="kde")
plt.savefig("robustscaler.png",dpi=200)
plt.close()
RobustScaler转换后数据变成这样
beta exp bignor nor
0 0.284395 -0.141315 0.551292 0.923234
1 0.126973 -0.278467 0.779068 0.790394
2 -0.674763 3.388036 0.313090 -1.150118
3 -0.502211 3.251365 1.234674 0.023211
4 0.262573 0.636202 0.729129 0.925553
分布为
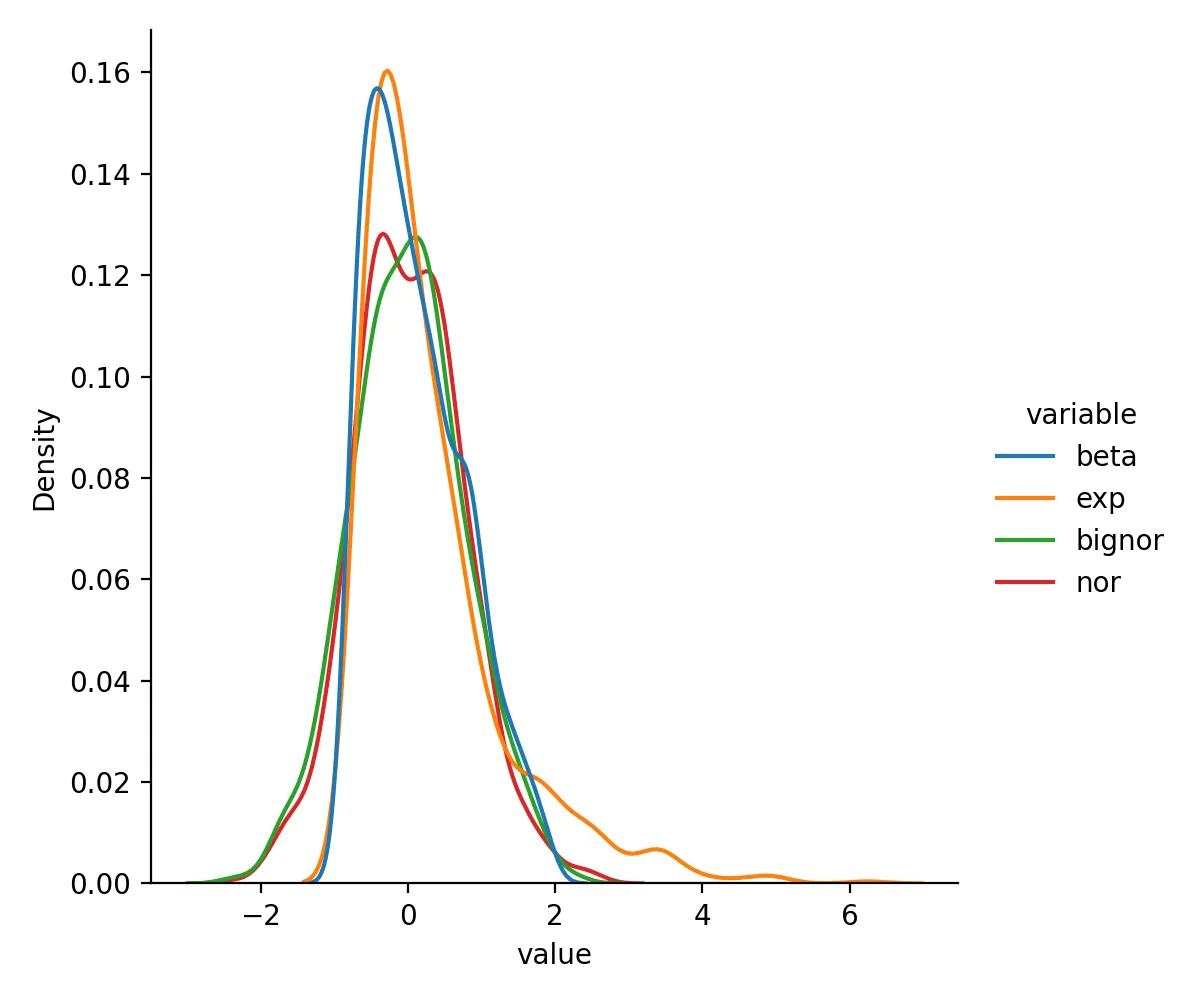
StandardScaler
from sklearn.preprocessing import StandardScaler
df_std = pd.DataFrame(StandardScaler().fit(df).transform(df), columns = df.columns)
sns.displot(df_std.melt(),x="value",hue="variable",kind="kde")
plt.savefig("standardscaler.png",dpi=200)
plt.close()
StandardScaler转换后数据变成这样
beta exp bignor nor
0 0.252859 -0.460413 0.711804 1.207845
1 0.012554 -0.600899 1.008364 1.030065
2 -1.211305 3.154733 0.401670 -1.566938
3 -0.947902 3.014740 1.601554 0.003337
4 0.219547 0.336005 0.943345 1.210949
分布为
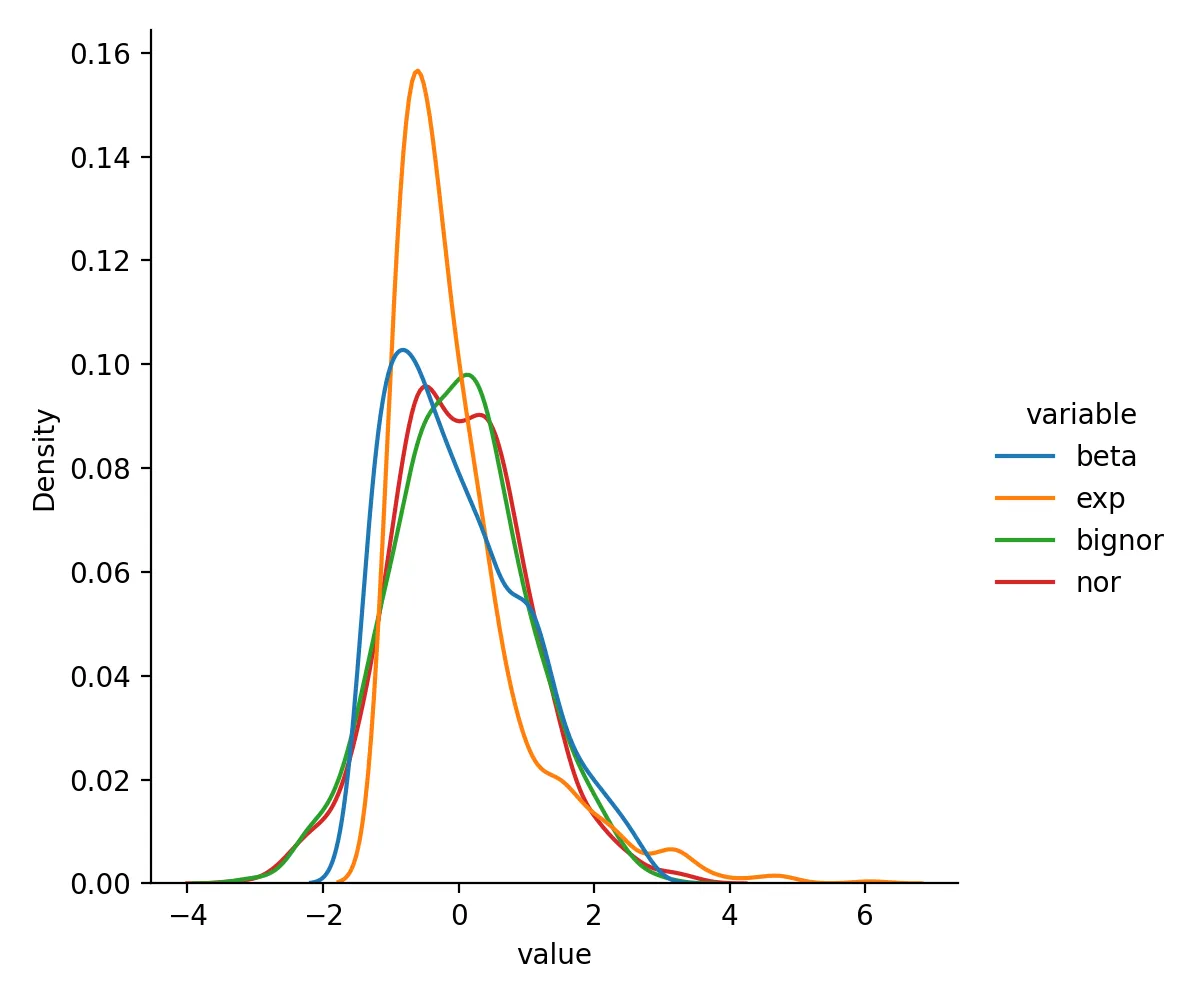
总结
该文中总结了多种标准化与归一化的方法,使用这些方法的好处以及它们对数据分布的影响,一般来说,使用standardize标准化是比较常见的做法.
- 原文作者:春江暮客
- 原文链接:https://www.bobobk.com/981.html
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。