最大回文字符串算法Manacher
在刷leetcode时有个求最长回文字符串的问题。……
春江暮客的个人学习分享网站
在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数,如果字符串是二进制的话,使用位运算异或可以非常简单的算出两字符串的汉明距离。
这里我们将介绍python3中如何使用二进制的使用以及二进制的位操作。
……在计算科学中,一个排序算法是一种能将一串数据依照特定排序方式进行排列的一种算法。最常用到的排序方式是数值顺序以及字典顺序。有效的排序算法在一些算法中是重要的。排序算法也用在处理文字数据以及产生人类可读的输出结果。
基本上,排序算法的输出必须遵守下列两个原则:1. 输出结果为递增序列(递增是针对所需的排序顺序而言) 2.输出结果是原输入的一种排列、或是重组
……在频率分布直方图中,当样本容量充分放大到极限时,组距极限缩短,这个时候频率直方图中的阶梯折线就会演变成一条光滑的曲线,这条曲线就称为总体的密度分布曲线。
这篇文章春江暮客将详细介绍如何使用python绘图库seaborn和panda里面的iris也就是鸢尾花卉数据集来绘制各种炫酷的密度曲线。
……词云,相信大家都看到过,这是一个使用python的著名的词云工具wordcloud库绘制而成的,本文将详细介绍如何使用wordcloud绘制中国四大名著之一的《红楼梦》的词云。
包括3部分:
直接上代码:
from wordcloud import WordCloud
import jieba
text = "".join(jieba.cut(open("红楼梦.txt").read()))
wordcloud = WordCloud(font_path="kaibold.ttf").generate(text)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.margins(x=0, y=0)
plt.show()

今天在使用python的seaborn画热图(clustermap)的时候,发现了总是出现这个错误,而且可以知道自己的数据完全是符合条件的,在搜索了谷歌后也没有找到好的解决方法,经过摸索后这里把最终解决方法告诉大家。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from seaborn import clustermap
import seaborn as sns; sns.set(color_codes=True)
df = pd.DataFrame([["a","b","c","d","e","f"],[1,2,3,4,5,6],[2,3,4,5,6,7],[3,4,5,6,7,8]], columns=list('ABCDEF')).T
df
g = sns.clustermap(df.iloc[:,1:],cmap="PiYG")
生成dataframe并转置后,出现类型错误,TypeError: ufunc ‘isnan’ not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ”safe”
……在python实现千千音乐mp3下载 后小伙伴使用发现很多音乐在千千音乐都搜不到,所以今天春江暮客就拓展了一下酷狗音乐的下载,有源码。
同样的配方,首先在酷狗官网上直接搜索歌曲,然后打开谷歌浏览器的网络监视器,再次搜索同样的关键字就可以发现接口信息(注:此处最好再次搜索的时候查看网络,可以剔除很多多余的信息)。
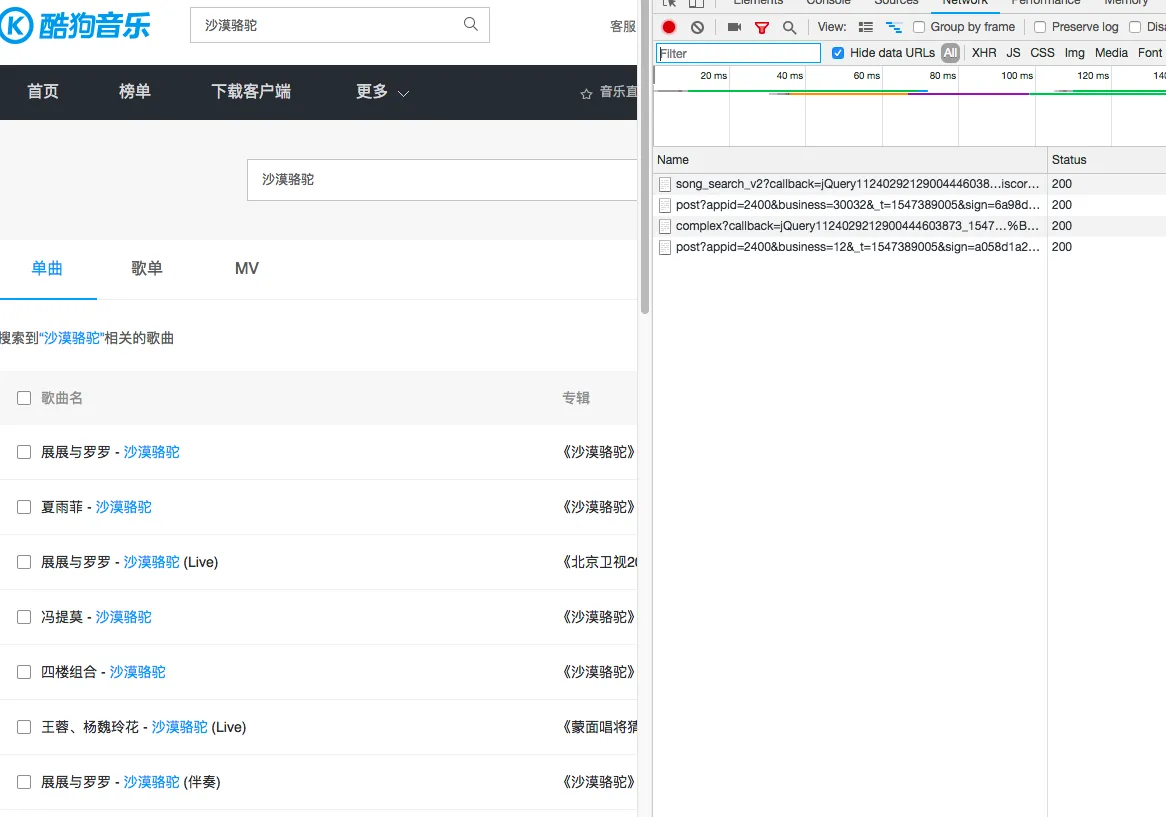 只有4条网络请求,可以很方便的知道是第一条请求是真正的返回了歌曲信息,因此构造此条请求即可。
只有4条网络请求,可以很方便的知道是第一条请求是真正的返回了歌曲信息,因此构造此条请求即可。
NetworkX是一个用于研究图形和网络的Python库。 NetworkX是根据BSD-new许可证发布的免费软件。可用于创造和操作复杂网络,学习复杂网络的结构及其功能。
有了NetworkX你就可以用标准或者不标准的数据格式加载或者存储网络,它可以产生许多种类的随机网络或经典网络,也可以分析网络结构,建立网络模型,设计新的网络算法,绘制网络。
……